資料前處理
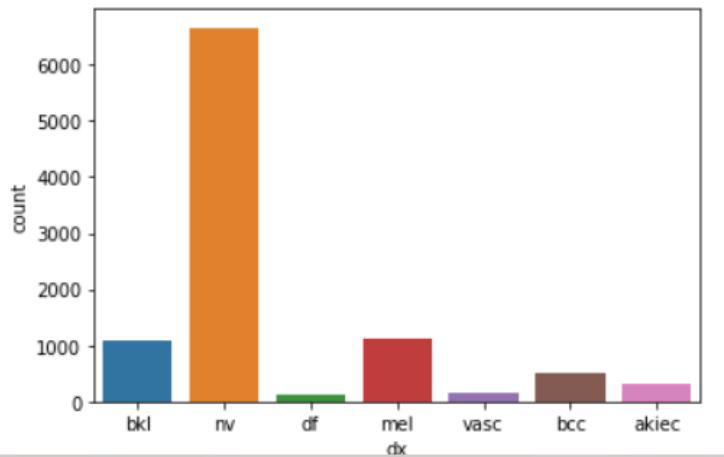
【圖十七】平衡前的皮膚疾病資料庫
由圖十七可見,黑素細胞痣(NV)是其他六種皮膚病的六倍以上,這問題若不解決,會造成overfitting,甚麼意思呢?就好比一名考生去考試,但他其實都沒讀書,但全猜NV也能考到60分以上,這樣非常不好,好在與老師討論後問題很快就解決了。
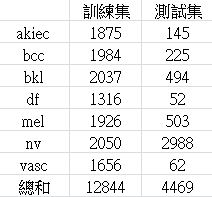
【圖十八】平衡後的皮膚疾病資料庫
圖十八就是平衡後的資料庫了,可以看到訓練集的NV已經平衡好了,而測試集的話不平衡也無訪,畢竟它只是考卷,漫長的前處理終於結束了,我們就趕快進行下一步吧!!!
圖片變形
這個步驟的目的在於讓圖片變多,比方說我只要將圖片旋轉90度,雖然在人類的認知上,它還是同一張圖片,但在電腦的眼裡,它已經是完全不同的兩張圖,利用這點,很容易就可以經資料庫的訓練集擴充到四倍以上。
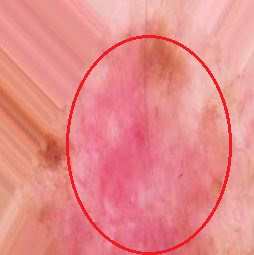
【圖十九】變形範例
上圖是我們從皮膚疾病的資料庫任選的一張,這光化性角化病(AKIEC)的變形範例,這張圖已經是平移旋轉,可以看到在變形的影響下,有的部分已經變得十分模糊,但這就是我們要的,紅色圈起處就是我們要讓CNN捕捉的特徵,只要那部分是清楚的就沒問題了。
模型建構
可以想像一下工廠生產線的輸送帶,是不是長得很像模型呢?那如果每個商品大小不一,就沒辦法送進機器裡,為此我們先把每張圖片設定成同樣大小100(長)*100(寬)*3(RGB),經過3個CNN抓取特徵,再把它攤平(Flatten),最後經由MLP分類(寶可夢5類、皮膚疾病7類),而分類又分成有排他性和無排他性,而我們要的結果是唯一的,因此activation選用softmax。

【圖二十一】皮膚疾病自建模型
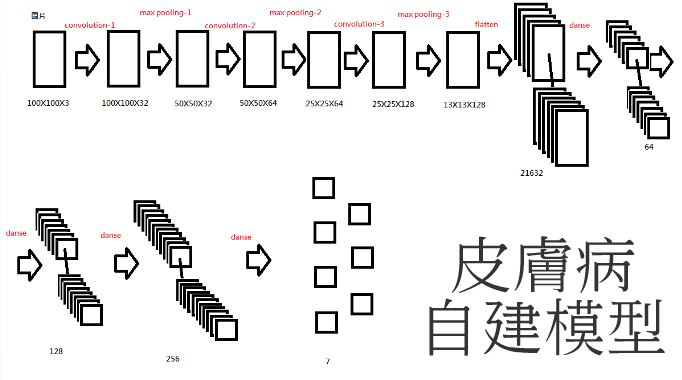
【圖二十二】皮膚疾病自建模型手繪版
這過程看似複雜且費時,但程式在從輸入圖片到結果分類,僅僅在彈指之間,因此我們會讓這過程進行幾百幾千,甚至是幾萬次,這就是電腦模仿人腦辨識的過程。
